
Das Multiplizieren und das Dividieren soll alleine von Shiften und von Addition und Subtraktion statt finden.
Man schaue sich zunächst folgende Fall an:
Ich dividiere durch
Code: Alles auswählen
100100b div 10b
Code: Alles auswählen
100100b >> 1
Code: Alles auswählen
100100b >> 2
100100b >> 10b
Code: Alles auswählen
100111b / 4
100111b >> 2
1001b (Ergebnis)
Das rausgeschiftete 11b Rest
Jetzt multipliziere ich zahlen
Code: Alles auswählen
*2 ^== << 1
*4 ^== << 2
*8 ^== << 3
Wenn ich mit
3 multpliziere ist das
x << 1 + x << 0
Ich multiplziere mit 1011b
x * 1000b + x * 10 b + x * 1b
^==
x << 3 + x << 1 + x << 0
Ziel unseres MIPS Assembler Programms ist eine Zahl
Code: Alles auswählen
ACode: Alles auswählen
BCode: Alles auswählen
CWeitere Ziele werden sein
- Arithmetisches Mittel bilden
- Geometrisches
- Reihen berechnen
- Einsen zählen
- Zum einen müssen wir Labels einführen - wir brauchen das, weil wir aus dem RAM laden
- Zum anderen müssen wir beim geometrischen Mittel, die Wurzel 2 anwenden. Dafür brauchen wir das Intervallhalbierungsverfahren. Es ist in der Mathematischen Einführung der Universität in Tübingen zu finden
- An dieser Stelle fällt es mir auf - dass es mit dem arithmetischen Mittel schwer wird. Jetzt brauchen wir nämlich fliesskommazahlen, aber wir können uns drum bemühen.
Wir brauchen ein Datensegment und ein Textsegment. Die Labels definieren wir wie üblich
Code: Alles auswählen
.data
a: .word 71283 ; dividend
b: .word 4 ; divisor
c: .word 0x00 ; quotient
r: .word 0x00 ; rest
.text
Code: Alles auswählen
.data
a: .word 0x1321 # dividend
b: .word 0x4 # divisor
c: .word 0x00 # quotient
r: .word 0x00 # rest
.text
lw $t0, a
lw $t1, b
sll $t2, $t0, $t1
sw c, $t2
Wenn wir durch
Code: Alles auswählen
8
Code: Alles auswählen
3 Bit
Code: Alles auswählen
lg_2(divisor)
Dies können wir auch ohne Multiplikation erreichen. Denn unser Links Shift ist an sich die Multiplikation. Ich stelle den Code vor
Code: Alles auswählen
.data
a: .word 0x1321 # dividend
b: .word 0x4 # divisor
c: .word 0x00 # quotient
r: .word 0x00 # rest
.text
lw $t0, a
lw $t1, b
li $t2, 1
sll $t3, $t0, 1
sw $t3, c
Code: Alles auswählen
swIn diesem Falle ist eine Multiplikation statt gefunden
Code: Alles auswählen
.data
a: .word 0x1321 # dividend
b: .word 0x4 # divisor
c: .word 0x00 # quotient
r: .word 0x00 # rest
.text
lw $t0, a
lw $t1, b
loop1:
sll $t0, $t0, 1
sll $t1, $t1, 1
beqz $t1 loop1
sw $t0, c
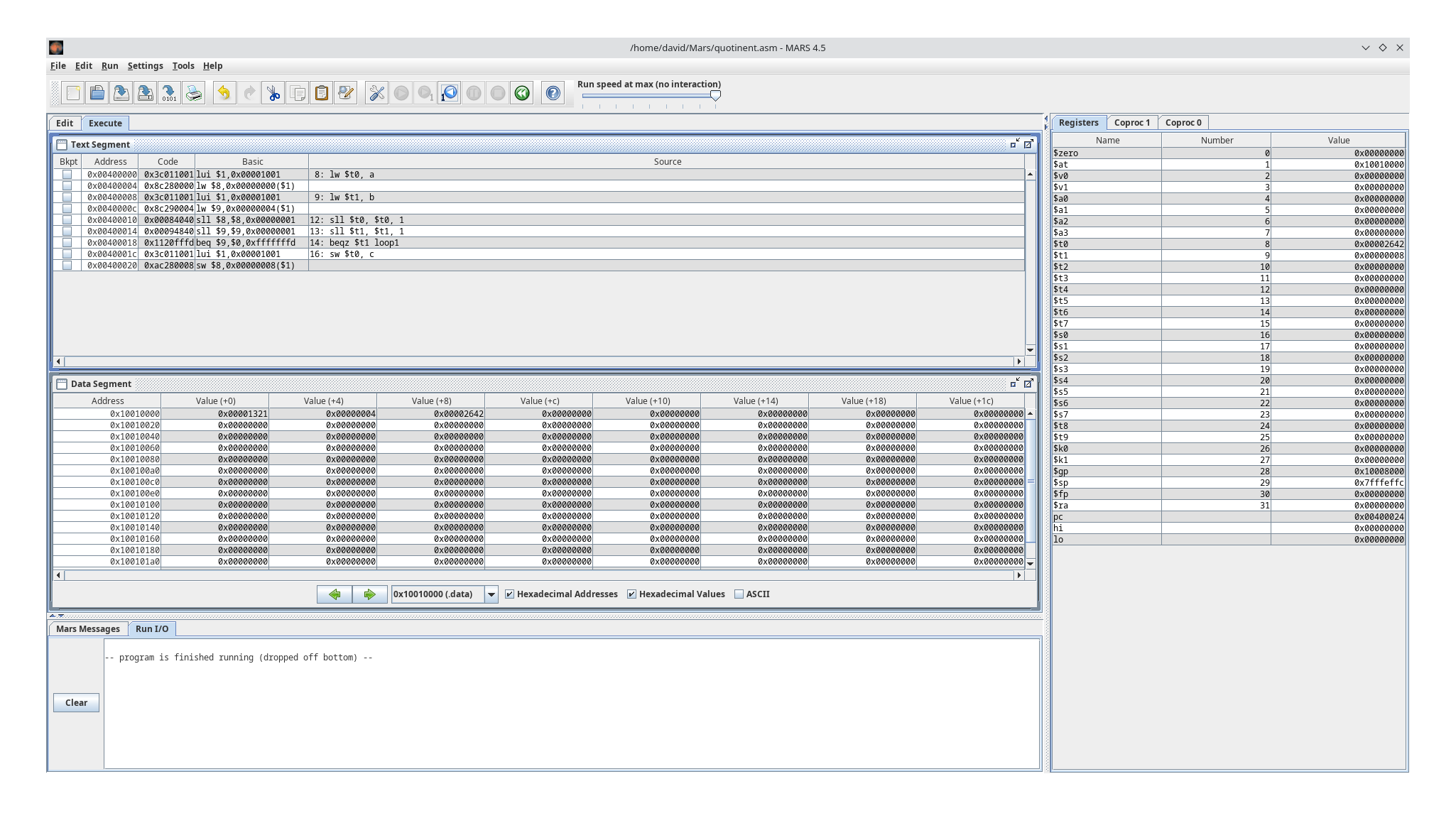
Was wir sehen sind im Arbeitsspeicher
Code: Alles auswählen
0x00001321
0x00002642
So wäre das Programm richtig
Code: Alles auswählen
.data
a: .word 0x1321 # dividend
b: .word 0x4 # divisor
c: .word 0x00 # quotient
r: .word 0x00 # rest
.text
lw $t0, a
lw $t1, b
loop1:
srl $t0, $t0, 1
srl $t1, $t1, 1
bnez $t1, loop1
sw $t0, c
Code: Alles auswählen
0x00001321
0x00000264
Zunächst wandeln wir die Zahlen ins Dezimalsystem um
Code: Alles auswählen
0x00001321
0x00000264
Code: Alles auswählen
0x00001321/0x00000264 = 0x4c8
Code: Alles auswählen
0x264
Code: Alles auswählen
bnez
Code: Alles auswählen
1
Eine andere Möglichkeit, anstatt mit
Code: Alles auswählen
1
So ist der Programmquelltext richtig
Code: Alles auswählen
.data
a: .word 0x1321 # dividend
b: .word 0x4 # divisor
c: .word 0x00 # quotient
r: .word 0x00 # rest
.text
lw $t0, a
lw $t1, b
srl $t1, $t1, 1
loop1:
srl $t0, $t0, 1
srl $t1, $t1, 1
bnez $t1, loop1
sw $t0, c
Allerdings geht das nur solange, man durch einen Wert
Code: Alles auswählen
0x02
0x04
0x08
...
Indem wir mit
Code: Alles auswählen
0b100100011100011
Code: Alles auswählen
1 * q
+ 10 * q
+ 100000 * q
+ ...
Nein, das war falsch. Wir müssen nicht mit dem geshifteten Multiplizieren. Wir müssen das Ergebnis bereits shiften. Aber wir müssen es inzwischen speichern, um zum alten Wert dazu zu addieren.
Ich habe das Programm zur Multiplikation so eben geschrieben
Code: Alles auswählen
.data
a: .word 1231 # Muliplikant
b: .word 17 # Multiplikator
c: .word 0x00 # Product
.text
lw $t0, a
lw $t1, b
li $t2, 0
loop1:
and $t3, $t1, 1
beqz $t3, notadd1
add $t2, $t2, $t0
notadd1:
sll $t0, $t0, 1
srl $t1, $t1, 1
bnez $t1, loop1
sw $t2, c
Code: Alles auswählen
0x4CF * 0x11 = 51BF